Cross-Episodic Curriculum for Transformer Agents
Lucy Xiaoyang Shi1 * Yunfan Jiang1 * Jake Grigsby2 Linxi "Jim" Fan3 † Yuke Zhu2 3 †
1Stanford University 2The University of Texas at Austin 3NVIDIA Research
*Equal contribution †Equal advising
Paper | Bibtex | Code
Neural Information Processing Systems (NeurIPS), 2023
|
We present a new algorithm, Cross-Episodic Curriculum (CEC), to boost the learning efficiency and generalization of Transformer agents. Central to CEC is the placement of cross-episodic experiences into a Transformer’s context, which forms the basis of a curriculum. By sequentially structuring online learning trials and mixed-quality demonstrations, CEC constructs curricula that encapsulate learning progression and proficiency increase across episodes. Such synergy combined with the potent pattern recognition capabilities of Transformer models delivers a powerful cross-episodic attention mechanism. The effectiveness of CEC is demonstrated under two representative scenarios: one involving multi-task reinforcement learning with discrete control, such as in DeepMind Lab, where the curriculum captures the learning progression in both individual and progressively complex settings; and the other involving imitation learning with mixed-quality data for continuous control, as seen in RoboMimic, where the curriculum captures the improvement in demonstrators' expertise. In all instances, policies resulting from CEC exhibit superior performance and strong generalization. |
Motivation
|
Transformers excel at recognizing patterns, but they struggle when there's limited data for learning agents. For complex tasks, agents either need abundant samples (RL agents) or demonstrations (IL agents), making it challenging in fields like robotics where data is scarce.
|
|
In IL settings, human demonstrations vary in quality, but still present patterns of improvement and generally effective manipulation skills among different operators: |
|
Traditionally, these cross-episodic patterns were overlooked. In this work, we leverage Transformers to extract the underlying improvement patterns and extrapolate for even further and faster improvement in embodied tasks. |
Method
|
CEC explicitly harnesses the shifting distributions of multiple experiences when organized into a curriculum.
a) policy improvement in single environments,
b) learning progress in a series of progressively harder environments, or c) the increase of demonstrators' proficiency. |
|
Subsequently, it causally distills the policy refinement and effective visuomotor skills into the model weights of Transformer agents through cross-episodic attention. This allows the policy, while predicting current actions, to trace back beyond ongoing trials and internalize improved behaviors encoded in curricular data. |
Experiment
|
We evaluated CEC's ability to improve sample efficiency and generalization across two primary case studies: |
Generalization gap between training and testing
|
For all DMLab levels, agents resulted from task-difficulty-based curricula are not trained or finetuned on test configurations. Therefore, their performance should be considered as zero-shot. |

|
DMLab Evaluation
|
For complex embodied navigation tasks, CEC outperforms well-known offline RL techniques, such as Decision Transformer (DT) and BC baselines trained using expert data, given the same parameters, architecture, and data size. Notably, CEC's performance exceeds RL oracles, which were directly trained on test task distributions, by at most 50% without prior exposure to such tasks, denoting its zero-shot capability. |
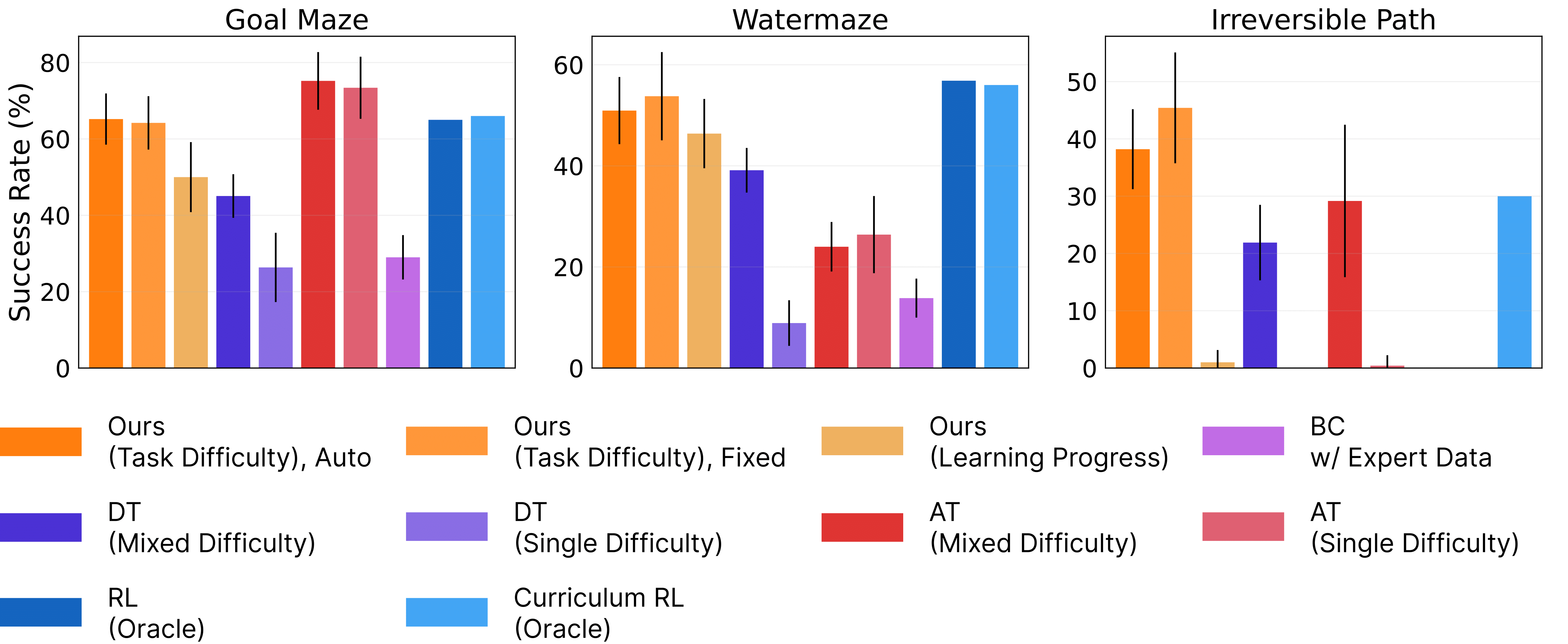
|
|
On average, our method with task-difficulty-based curriculum performs the best during evaluation, confirming the benefit over the concurrent AT approach that leverages chain-of-hindsight experiences. When compared to DT, it outperforms by a significant margin, which suggests that our cross-episodic curriculum helps to squeeze learning signals that are useful for downstream decision-making. |

|
DMLab Generalization
|
CEC leads to robust policies, improving by up to 1.6x over RL oracles when probed with novel test settings, such as unseen maze mechanism, out-of-distribution difficulty, and different environment dynamics. |
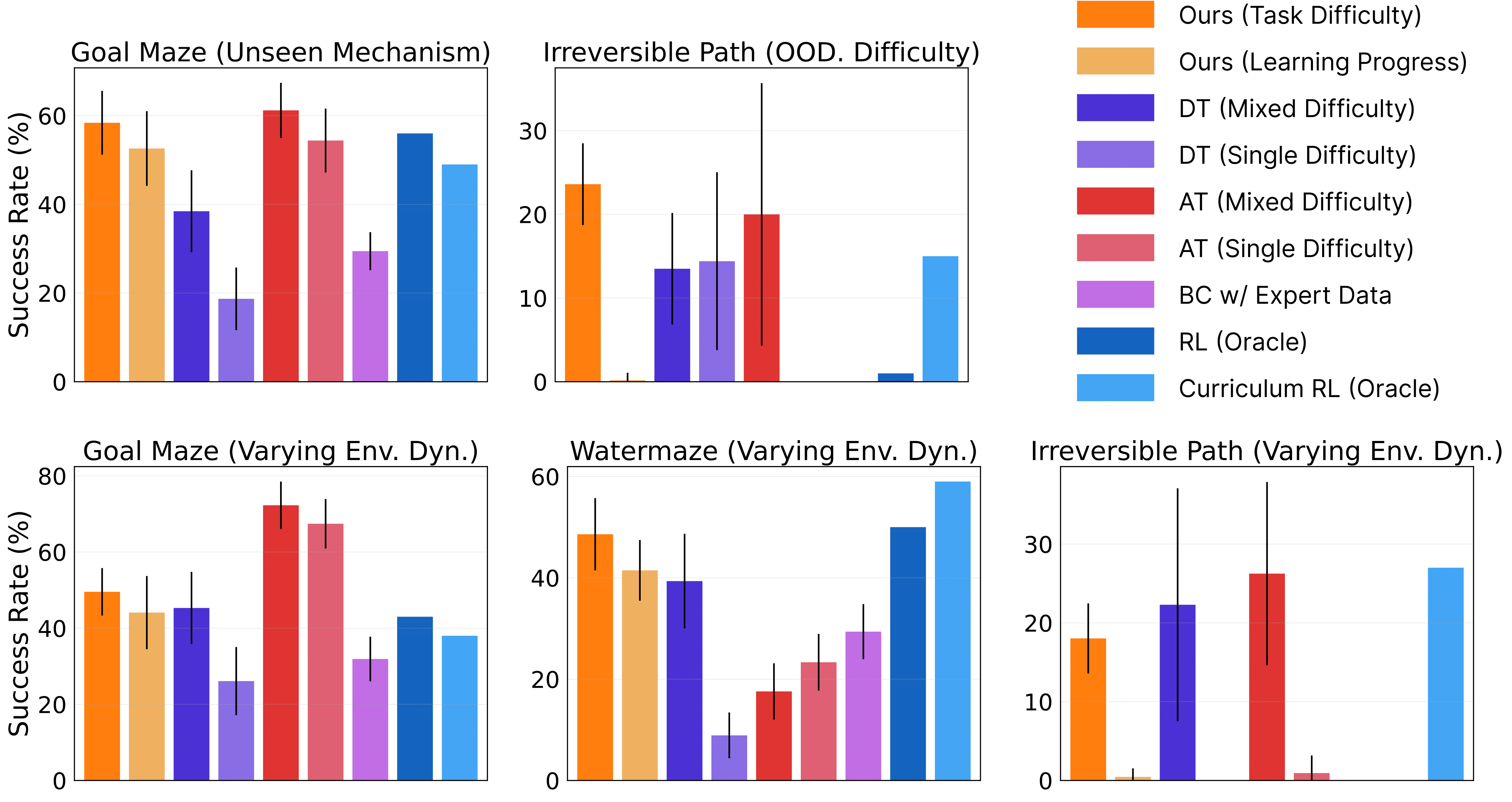
|
|
On average, our method surpasses the concurrent AT baseline and achieves significantly better performance than other baselines. This empirically suggests that CEC helps to learn policies that are robust to environmental perturbations and can quickly generalize to new changes. |

|
Continuous Robotic Control
|
CEC successfully solves two simulated robotic manipulation tasks, matching and outperforming previous well-established baselines. |

|
Ablation
|
An essential factor in our success was the cross-episodic attention. Ablation studies revealed that without it, the performance of Transformer agents trained on the same suboptimal data dropped markedly, emphasizing its essential role in performant policies. Please refer to our paper for more ablations. |

|
Qualitative Performance Comparisons
|
We visualize different policies on Irreversible Path, one of the hardest tasks in DMLab. |
Ours (Task-Difficulty) |
Decision Transformer |
Agentic Transformer |
Conclusion
|
In this work, we introduce a new learning algorithm named Cross-Episodic Curriculum to enhance the sample efficiency of policy learning and generalization capability of Transformer agents. It leverages the shifting distributions of past learning experiences or human demonstrations when they are viewed as curricula. Combined with cross-episodic attention, CEC yields embodied policies that attain high performance and robust generalization across distinct and representative RL and IL settings. CEC represents a solid step toward sample-efficient policy learning and is promising for data-scarce problems and real-world domains. |
Citation
|